샘플 데이터에 딱 맞는 그래프(몇 개의 데이터에 집착한 모델)은 새로운 데이터에 적응하지 못해 좋지 못한 성능을 가짐
-> 이럴 때, 규제를 사용해 가중치를 제한하면 일반화 성능을 향상시킬 수 있다.
가중치 규제
- 가중치 값이 커지지 않도록 제한하는 기법
- 가중치 규제하면 모델의 일반화 성능이 높아진다.
L1 규제(식은 책 참고)
- 솔실 함수에 L1 노름을 더하면 L1 규제 만들어진다.
- 손실 함수에 가중치의 절댓값인 L1 노름을 추가한다.
- L1 노름의 n은 가중치 개수를 의미
- 알파 값이 크면 전체 손실함수 값이 커지지 않도록 w값의 합이 작아져야 한다. => 규제가 강해진다.
- 알파 값이 작으면 w의 합이 커져도 손실 함수 값이 큰 폭으로 커지지 않는다 => 규제가 약해진다.
L1 규제 미분(식은 책 참고)
- w 절댓값에 대해 미분하면 부호만 남는다. => sign(w)
- L1 규제를 적용한 손실 함수의 도함수에 학습률을 곱하여 학습률을 적용할 수 있다.
- 규제 하이퍼파라미터(모델이서 설정해야하는 값)와 가중치 부호를 곱해서 수정할 그레이디언트 값에 더해주면 된다.
=> w_grad = w_grad + alpha * np.sign(w)
np.sign(w)는 배열 요소의 부호를 반환한다.
절편에 대해서는 규제를 하지 않는다!! -> 절편이 복잡도에 영향을 주지 않기 때문
- SGDClassfier 클래스에서는 penalty 매겨변수로 l1을 지정하는 방법 쓸 수 있다.
라쏘 모델
- 회귀모델에 L1 규제를 추가한 것
- 라쏘는 가중치를 0으로 만들 수도 있다.
- 가중치가 0인 특성은 모델에서 사용할 수 없다는 것과 같의 의미 => 특성 선택하는 효과임
- L1 규제는 하이퍼파라미터인 알파에 의존한다.
- L1은 가중치 크기에 따라 규제의 양이 변하지 않으므로 규제 효과가 좋지 않다.
L2 규제(식은 책 참고)
- 손실 함수에 L2 노름의 제곱을 더하면 L2 규제 만들어진다.
- 손실 함수에 가중치에 대한 L2 노름의 제곱을 추가한다.
- L1 노름의 n은 가중치 개수를 의미
- 알파 값이 크면 전체 손실함수 값이 커지지 않도록 w값의 합이 작아져야 한다. => 규제가 강해진다.
- 알파 값이 작으면 w의 합이 커져도 손실 함수 값이 큰 폭으로 커지지 않는다 => 규제가 약해진다.
L2 규제 미분(식은 책 참고)
- L2 규제를 미분하면 간단히 가중치 벡터 w 만 남는다.
- L2 규제를 경사 하강법 알고리즘에 적용할 수 있다.
- 그레이디언트에 알파와 가중치의 곱을 더하면 된다.
=> w_grad = w_grad + alpha * w
그레이디언트 꼐산에 가중치 값 자체가 포함되어 L1보다 효과적이다.
가중치를 완전히 0으로 만들지 않는다
릿지 모델
- 회귀모델에 L2 규제를 적용한 것
- 릿지는 SGDClassifier 클래스에서 penalty 매개변수를 l2로 지정하여 L2규제를 추가할 수 있다.
- L2 규제는 하이퍼파라미터인 알파에 의존한다.
- 규제 정도는 알파 매개변수로 제어한다.
로지스틱 회귀에 규제 적용

init() 함수에 L1, L2 규제 강도를 조절하는 매개 변수 추가. 기본값은 0으로 설정(규제 적용 X)
fit() 함수에서 역방향 계산 수행할 때, 그레이디언트의 패널티에 미분값을 더한다.
L1, L2 규제를 따로 적용하지 않고 하나의 식으로 작성하여 규제를 동시에 수행할 수 있다.
위 함수에서는 둘을 동시에 수행하도록 했다.
로지스틱 손실함수를 계산할 때, 패널티 항에 대한 값을 더해야 한다.
reg_loss() 함수를 클래스에 추가하여 훈련세트의 로지스틱 손실 함수의 값과 검증 세트의 로지스틱 손실 함수의 값을 계산할 떄 모두 호출하도록 한다.
위 함수는 검증 세트의 손실을 계산하는 함수다.
reg_loss()를 호출한다.
이제 규제 적용을 위한 사전 작업을 마쳤다.
L1 규제 적용

L1 규제 강도에 따른 모델 학습 곡선과 가중치가 어떻게 바뀌는지 확인해볼 수 있다.
강도(0.0001, 0.001, 0.01) for 반복문 사용해 각각 다른 강도의 하이퍼파라미터로 모델을 만들고 그래프 작성했다.
곡선 그래프들 보면, 규제가 커질 수록, 훈련 세트의 손실과 검증 세트의 손실이 모두 높아진다.
=> 과소적합
가중치 그래프를 보면 규제 강도가 커질수록 가중치 값이 0에 수렴하는 것을 볼 수 있다.
규제 정도를 0.001로 설정한 모델의 성능을 확인해보면, 규제를 적용했을 때와 적용하지 않았을 때 값이 동일하다.
이는 데이터 셋이 작아 규제 효과가 크게 나타나지 않기 때문이다.
L2 규제 적용

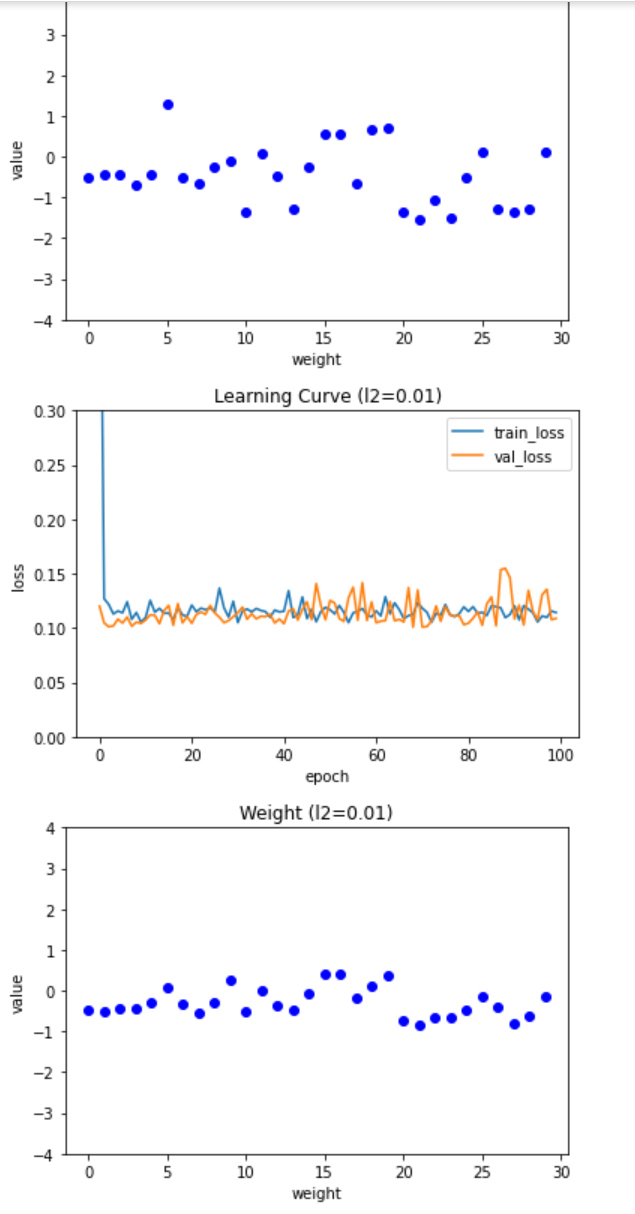
L2 규제 강도에 따른 모델 학습 곡선과 가중치가 어떻게 바뀌는지 확인해볼 수 있다.
강도(0.0001, 0.001, 0.01) for 반복문 사용해 각각 다른 강도의 하이퍼파라미터로 모델을 만들고 그래프 작성했다.
L1규제와 비슷하지만 규제강도가 강해져도 L1 규제만큼 과소적합이 심해지지 않는다.
규제 정도를 0.01로 설정한 모델의 성능을 확인해보면, 규제를 적용했을 때와 적용하지 않았을 때 값이 동일하다.
이는 데이터 셋이 작아 규제 효과가 크게 나타나지 않기 때문이다.
데이터 셋이 작아 L1, L2 규제 차이가 없다.
그러나, L2가 에포크가 많이 늘었다. -> 가중치를 강하게 제한했기 때문
검증 세트의 손실 값을 일정 수준으로 유지하면서 알고리즘이 전역 최솟값을 찾는 과정을 오래 반복하는 것이다.
SGDClassifier 클래스도 L1, L2 규제를 지원한다. 그 외 여러 클래스에서 규제를 지원한다.
교차 검증의 원리
전체 데이터 셋의 샘플 수가 적은 경우, 검증 세트를 분리하느라 훈련 세트의 샘플 수가 줄어들다...
이런 경우 교차 검증을 사용하면 좋다!!
* 폴드 : 교차검증할 때, 훈련 세트를 작은 덩어리로 나누는데, 그 덩어리를 폴드라고 한다.
교차검증 과정
1. 훈련 세트를 k개의 폴드로 나눈다.
2. 첫 번째 폴드를 검증 세트로 사용 하고 나머지는 훈련세트롤 사용한다.
3. 모델을 훈련 다음 검증 세트로 평가한다.
4. 순차적으로 다음 폴드를 검증 세트로 사용하여 반복한다.
5. k개의 검증 세트로 k번 성능 평가한 수, 계산된 성능의 평균을 내어 최종 성능을 계산한다.
k개로 나누어 k-폴드 교차 검증 이라고도 한다.
k-폴드 교차 검증 구현
k-폴드 교차 검증은 검증 세트가 훈련세트에 포함된다.
그러므로, 전체 데이터 셋을 다시 훈련 세트와 테스트 세트로 1번만 나누어 훈련과 검증에 사용한다.
각 폴드의 검증 점수 저장을 위한 리스트 변수를 선언했다.
교차 검증을 위한 반복문을 구현했다.
start는 검증 폴드 샘플의 시작이고, end는 끝 인덱스이다.
나머지 부분이 훈련 폴드 샘플의 인덱스이다.
위 내용으로 만든 훈련 폴드 샘플의 인덱스로 train_fold와 train_target을 만든다.
성능의 평균을 np.mean()으로 계산한다.
훈련 데이터의 표준화 전처리를 폴드를 나눈 후에 수행한다는 점을 기억하자.
사이킷런으로 교차 검증 구현
사이킷런의 model_selection 모듈에는 cross_validate() 함수가 있다.
SingleLayer에서 위 함수를 사용하려면 수정을 조금 해주어야 한다.
cross_validate() 함수로 교차 검증 점수 계산
함수의 매개변수로 교차 검증을 원하는 모델의 객체, 훈련 데이터, 타깃 데이터를 넣는다.
cv 매개변수에 교차검증을 수행할 폴드 수를 지정한다.
그리고 SGDClassifier 모델과 동일한 매개변수를 사용해 모델 객체를 만들고 교차 검증을 수행한다.
전처리 단계를 포함한 교차 검증
Pipeline 클래스 사용해 교차 검증
전처리 단계와 모델 클래스를 연결해주는 클래스 => Pipeline 클래스
표준화 전처리 단계와 SGDClassifier 객체를 Pipeline 클래스로 감싸 cross_validate()에 전달하면
훈련세트를 훈련 폴드와 검증 폴드로 나누기만 하고 전처리 단계는 Pipeline 클래스에서 이루어진다.
make_pipeline() 함수로 파이프라인 클래스 객체를 생성할 수 있다.
이를 사용하면 평균 검증 점수가 높아진 것을 확인할 수 있다.
'STUDY > 인공지능' 카테고리의 다른 글
| [6주차] 신경망 알고리즘 벡터화 (0) | 2021.05.25 |
|---|---|
| [4주차] 검증세트, 전처리, 과대적합과 과소적합 (0) | 2021.05.11 |
| [3주차]데이터 세트 분류, 로지스틱 회귀과 단일층 신경망 관계 (0) | 2021.05.04 |
| [2주차] 손실함수와 경사하강법의 관계, 선형회귀를 위한 클래스 생성, 퍼셉트론, 아달린, 로지스틱 회귀, 시그모이드 함수, 로지스틱 손실 함수 (0) | 2021.04.02 |
| [1주차] 코랩 사용법, 선형 회귀, 경사하강법 (0) | 2021.03.28 |



